「世の中には難しいことが多い!」と感じることが多い私が、様々な用語を、初学者向けにわかりやすく、全力で解説します。
今回解説する用語
BigQueryのジョブの基本的な概念について、構成図を交えながらわかりやすく解説をします!BigQueryを使用するにあたり、どのような権限を付与しなければならないのかについても記載します。
Bigqueryの構成
BigQueryは以下の図のようにストレージ機能とコンピューティングの機能が分かれています。
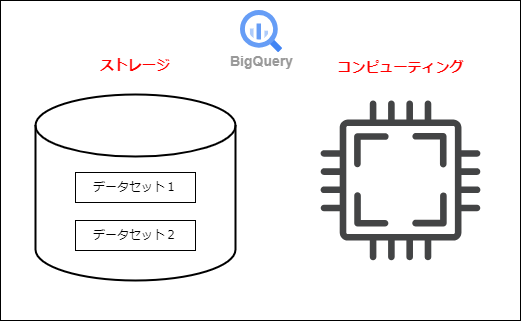
ストレージ機能とは、データを保存する機能のことです。BigQueryではデータセットという単位でデータが管理されます。データセットにテーブルを作成し、データを投入していきます。
コンピューティング機能とは、ストレージのデータに対して処理を実行してくれる機能のことです。SQLクエリを実行したり、データのコピーなどをジョブを作成し、実行してくれます。
ストレージ機能とコンピューティング機能が分離していることにより、それぞれの機能ごとにスケーリングをすることが出来ます。BigQueryはこのような構成のため、大量のデータを保存したり、高速に処理を実現することが出来ます。そのため、データの蓄積や分析をするデータ分析に有効なプロダクトとなっているのです。
BigQueryのロケーション
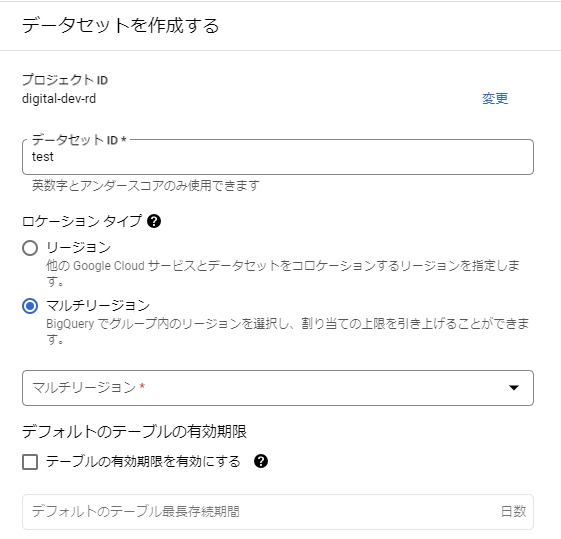
BigQueryはデータセットごとにロケーションを選択することが出来ます。
以下の画像のようにリージョンかマルチリージョンを選択することが出来ます。
BigQueryのジョブとは?
ジョブとは、BigQueryのコンピューティング機能で実行される処理のことです。ジョブには、SQLクエリの実行やデータの読み取り、データのコピーなどがあります。つまり、BigQueryを使いたい場合はジョブを作成する必要があるのです。
例えば、ユーザーがGoogle Cloud コンソールや bqコマンドを使用してSQLクエリを実行することで、BigQueryがユーザーに代わってジョブを自動的に作成し、順番に実行してくれるのです。

BigQueryでは、プロジェクトのすべてのジョブについて 6 か月分のジョブ履歴が保存されます。以下の手順で、BigQueryで実行されたジョブを確認することが出来ます。
https://cloud.google.com/bigquery/docs/managing-jobs?hl=ja#list_jobs_in_a_project
ジョブを確認してみよう
GoogleCloudコンソール上からジョブが作成されているのを確認してみます。
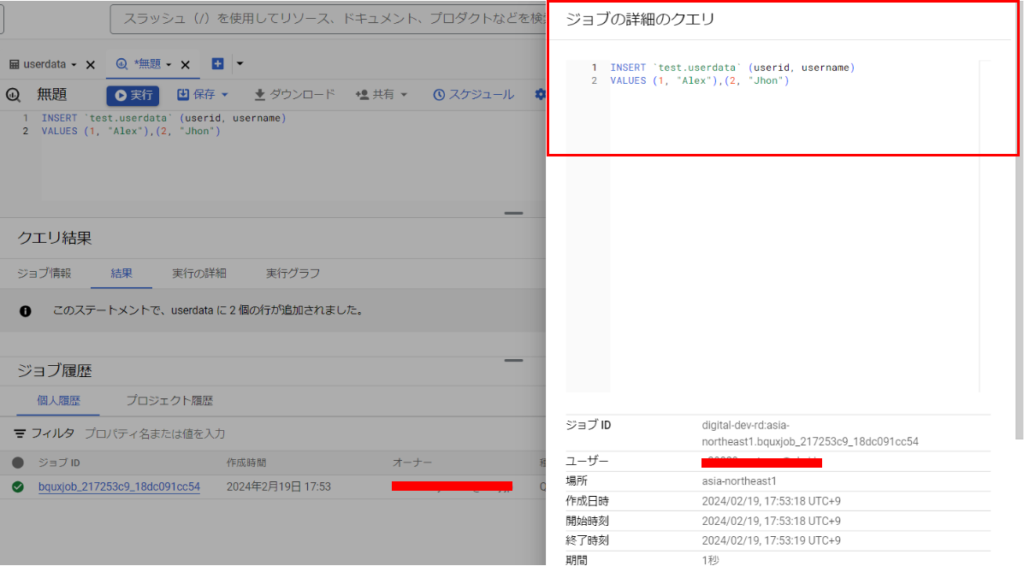
以下のようなSQLクエリを実行すると、「ジョブ履歴」からジョブが作成されているのが確認できます。
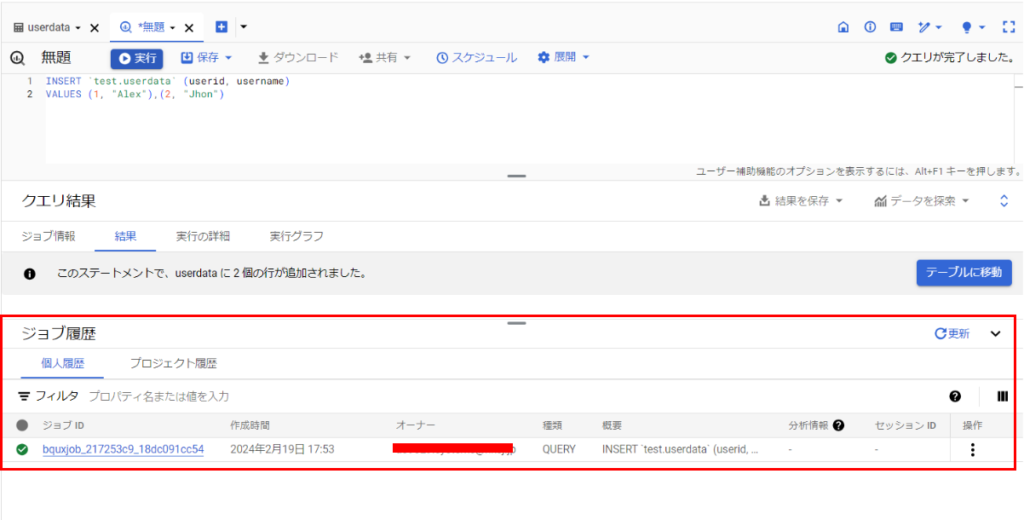
「ジョブID」を押下するとジョブの詳細を確認することが出来ます。
ジョブの実行権限とデータアクセス権限
BigQueryはジョブを実行する権限とデータにアクセスする権限が分かれています。
例として、データを読み込むSELECT分などのSQLを実行するケースを考えていきましょう。
データを読み込むSQLを実行する処理は以下の2ステップに分けることが出来ます。
- データを読み込むSQLを実行するためのジョブを実行する
- データが保存されているストレージ(データセットやテーブル)へアクセスをする
BigQueryではこの2ステップにそれぞれ権限が必要なのです。
- データを読み込むSQLを実行するためのジョブを実行する⇒ジョブを実行する権限
- データが保存されているストレージ(データセットやテーブル)へアクセスをする⇒データにアクセスする権限
この考え方を理解しておかないと、「ジョブを実行する権限(bigquery.jobs.create)を付けたのにSQLクエリが実行できない!」ということになります。
データアクセス権限
データへのアクセス権限はデータの読み取り権限(bigquery.tables.getData)や書き込み権限(bigquery.tables.updateData)のように分かれています。
また、プロジェクト、データセット、テーブルなどの単位で付与することが出来ます。例えば、Aさんに対してデータセット1へのデータの読み取り権限だけを付与することも出来ます。
詳細の権限については、以下の公式ドキュメントを確認してみてください。
https://cloud.google.com/bigquery/docs/access-control-basic-roles?hl=ja