日頃から「世の中には難しいことが多い!」と感じる私が、様々な用語を、「誰にでも」「なんとなく」理解できるように全力で解説します!
Spannerとは?
Spannerとは、Google Cloudが提供する、グローバルかつ無制限にスケーリング出来る、フルマネージドなリレーショナルデータベースです。そういわれても何が良いのか分からない、、という方に向けて、本記事ではSpannerのすごいところを具体的に説明をしていきます。

Spannerのすごいところとは?
かんたんに増えたり減ったりすることが出来る
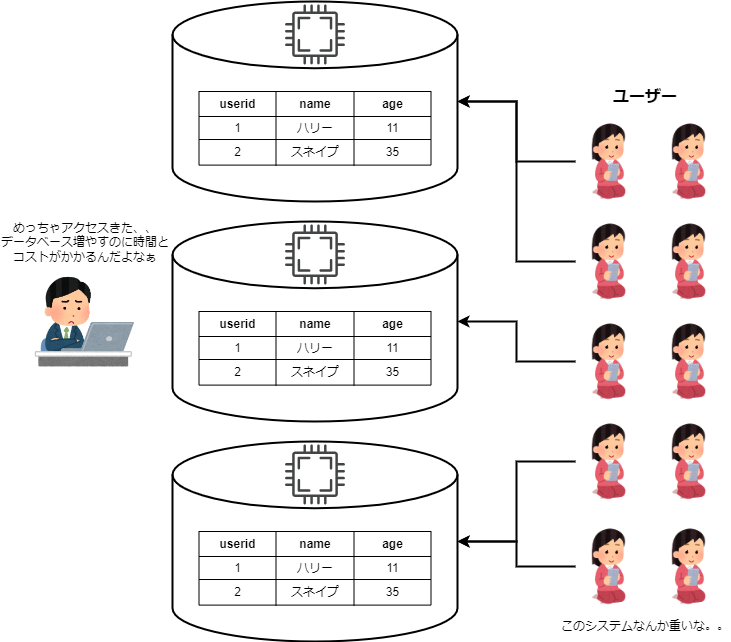
通常のデータベースの場合は、以下の図のようにストレージとコンピューティングの機能がセットになっています。

ストレージ機能とは、データを保存する機能のことです。RDBの場合は、上の図のストレージのようになじみの深い形式でデータが保存されます。
コンピューティング機能とは、ストレージのデータに対して処理を実行してくれる機能のことです。SQLクエリを実行したり、データのコピーなどをしてくれます。
通常のデータベースはコピーを増やしたい場合は、以下の図のようにコンピューティングとストレージどちらも増やさなければならないので、かなり増えにくいです。増やすためには時間と無駄なコストがかかってしまいます。
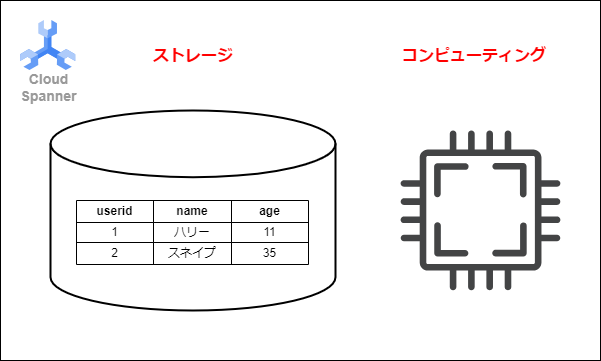
Spannerは以下の図のようにストレージ機能とコンピューティングの機能が分かれています。
Spannerはストレージ機能とコンピューティング機能が分離しているため、かんたんに増えたり減ったりすることが出来るのです。このように同様の構成のデータベースが柔軟に増えたり減ったりすることで負荷分散になり、アプリケーションの可用性を向上させることが出来ます。
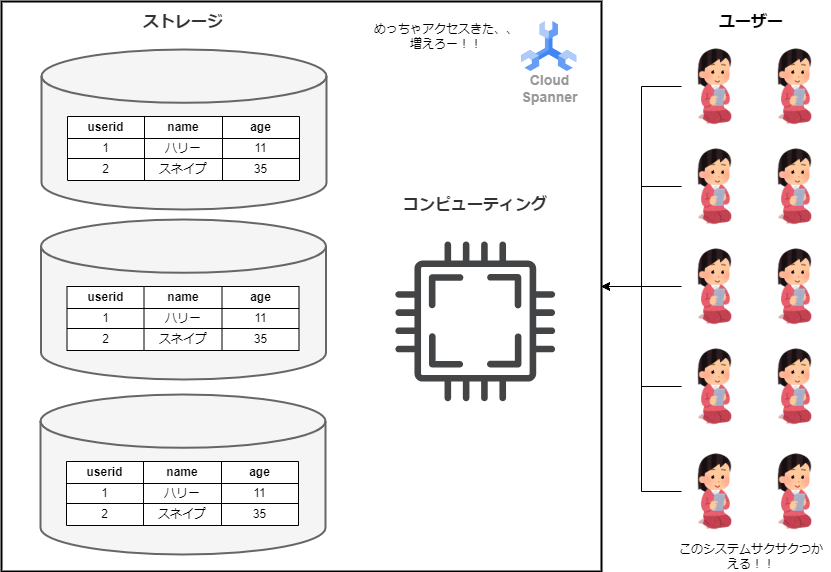
上の図では、3つにスケーリングしていますが、実際は無制限にスケーリングをすることが出来ます。
強力な整合性と一貫性を持つ
リレーショナルデータベース(RDS)はデータの整合性を保つのに最適なデータベースです。絶対にデータの不整合が発生してはいけないシステムではRDSが採用されます。
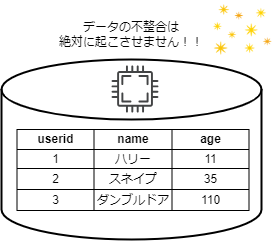
その代わり、RDSは水平スケーリングがしにくいといわれています。理由として、データの整合性を保つのが難しいからです。
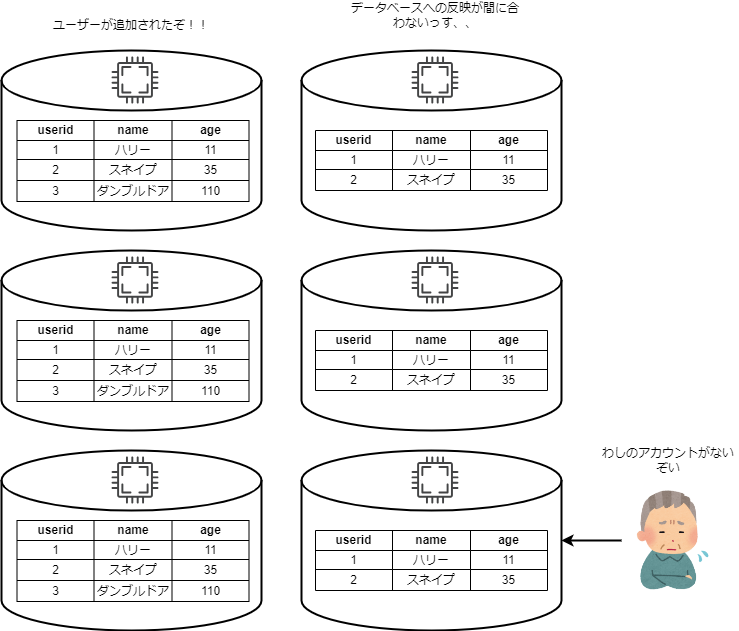
例えば、新たに「ダンブルドア」というユーザーをデータベースに追加するとします。データベースは6つにスケーリングしています。この場合、6つのデータベースすべてにダンブルドアというユーザーが追加されていなければなりません。すべてのデータベースに変更を反映するのには時間がかかります。そのようなことから、通常のRDSだと複数のスケーリングしたデータベースでデータの整合性を保つのが苦手と言われています。
Spannerではこのようなデメリットを解消されています。RDSでありながら、スケーリング後でもデータの整合性を保つことが出来る、まさに夢のようなデータベースなのです。
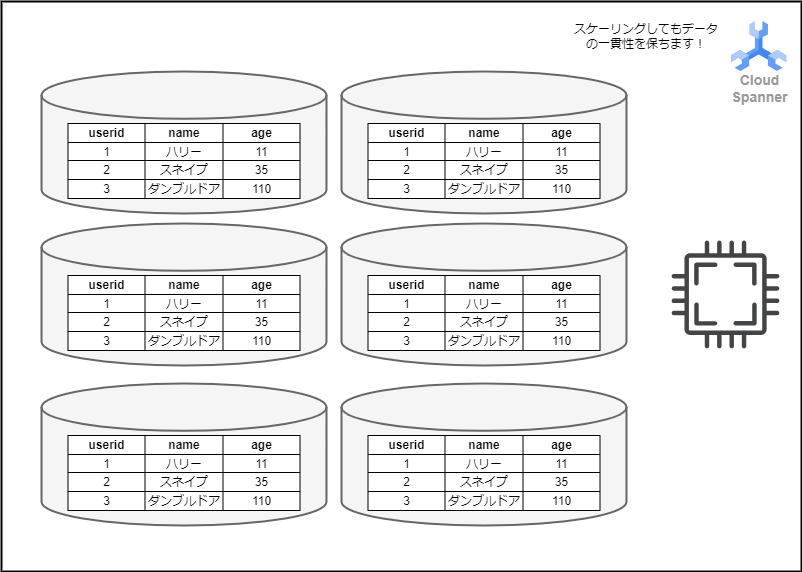
このように柔軟にスケーリングが可能のため、アクセスの予測が難しいシステムでも、無駄を発生させず、リソースを最適化することが出来るのです。
世界中に増えたり減ったりすることが出来る
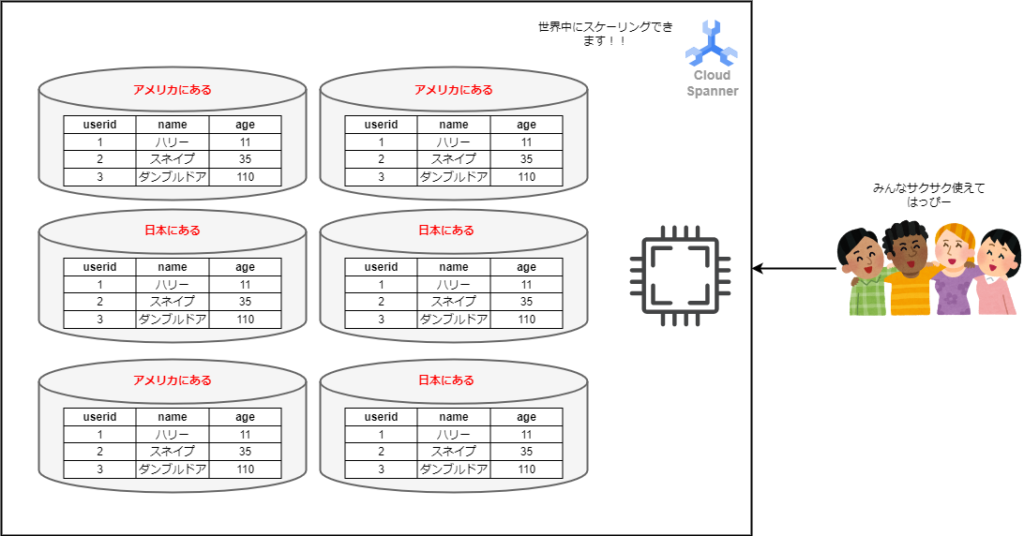
また増えたり減ったりかよ、、と思うかもしれませんが、Spannerは世界中に増えることが出来ます。かっこよくいうと、グローバルにスケーリングすることが出来ます。これにより世界中のユーザーが遅延なくデータベースにアクセスすることが出来るのです。
フルマネージドでかんたんに使える
「すごいのは分かったけれども使うの難しいんでしょう??」と思われたあなた、いえいえそんなことはありません。SpannerはGoogle CloudのWebコンソールから直感的に操作することが出来ます。また、RDSなので通常のSQLクエリで使用することが出来ます。実際の画面は後程お見せします。
さらにSpannerはフルマネージドになっていて、ユーザーがメンテナンスをする必要はありません。まさに至れり尽くせりですね。
実際の画面を見てみよう
実際の画面をGoogle CloudのWEBコンソールから見てみましょう。Spannerを使用して、データベースを作成してみます。
まずはSpannerの画面から「プロビジョニングされたインスタンスの作成」を押下し、インスタンスを作成します。
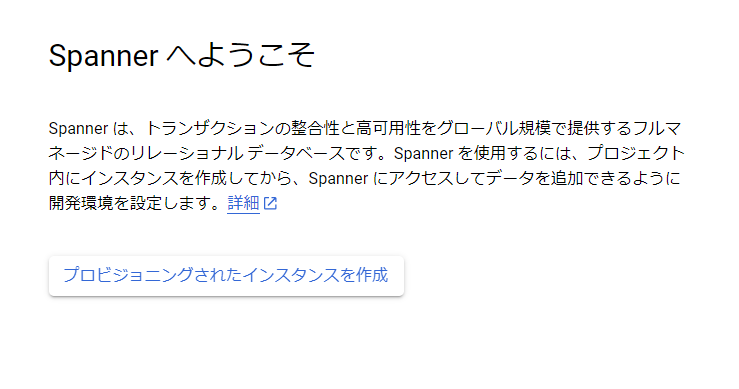
「インスタンス名を指定する」画面ではインスタンスの名前とインスタンスIDを入力します。
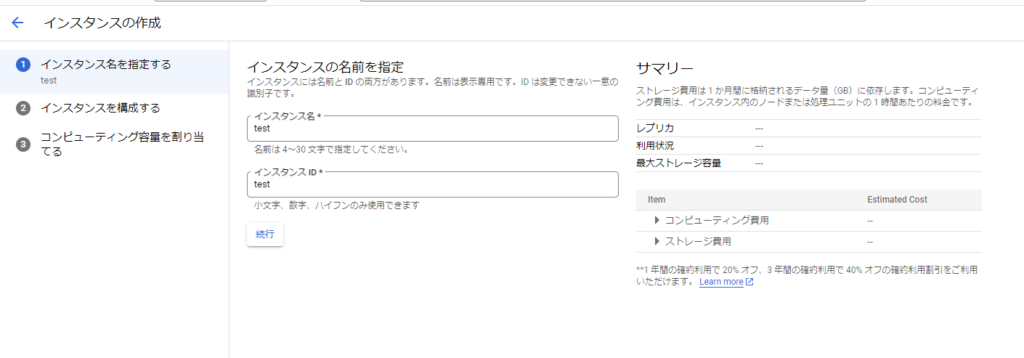
「インスタンスを構成する」画面でインスタンスのロケーションを選択することが出来ます。マルチリージョンを選択することで可用性を向上させることが出来ます。
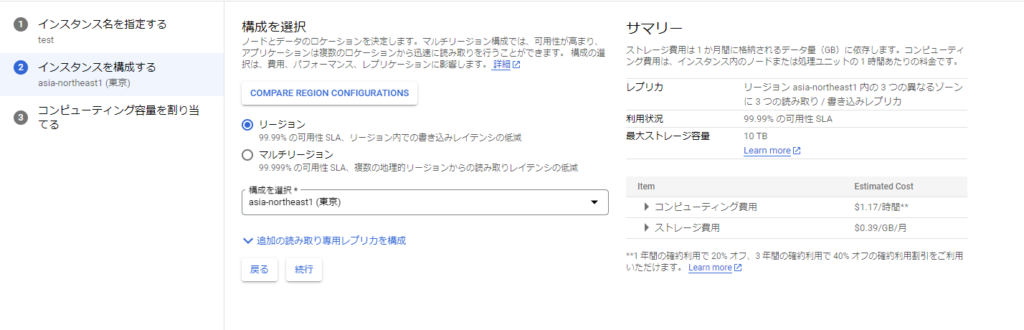
コンピューティングの容量を割り当てます。こちらの画面ではスケーリングするための設定を入力することが出来ます。以下の画像では1~10の間でスケーリングをするように設定しています。これで作成ボタンを押下することでインスタンスが作成されます。
次にデータベースを作成しましょう。データベースの作成を押下し、必要な情報を入力していきます。「DDLテンプレート」から「テーブルを作成」を押下することで、テーブルを作成するためのテンプレートクエリが自動で入力されます。
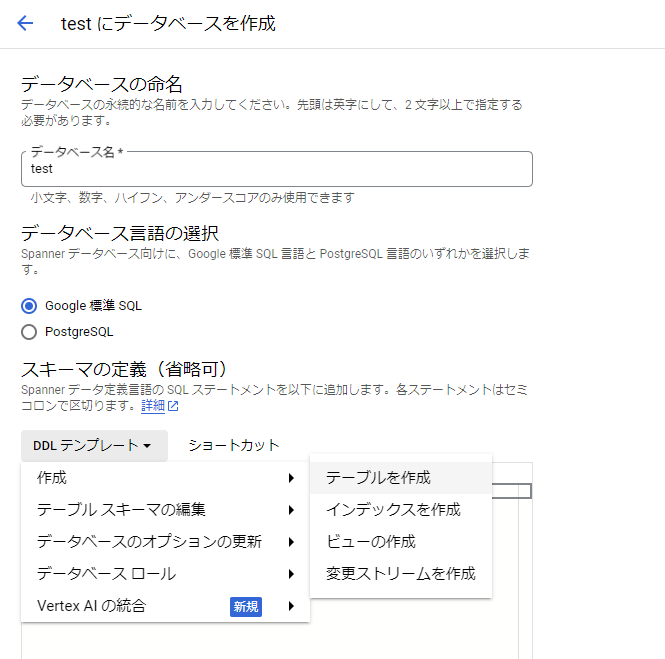
作成するテーブルのクエリを入力し、「作成」を押下することでデータベースが作成されます。
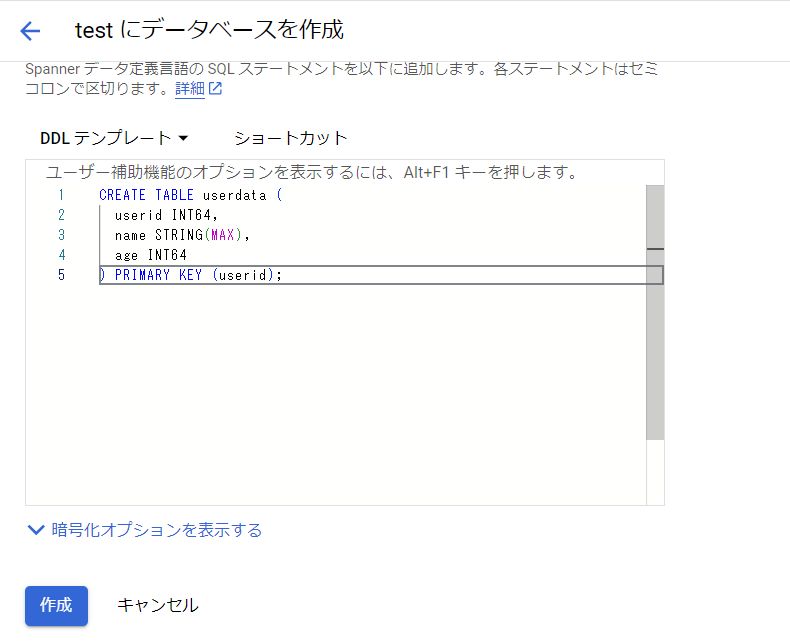
データベースとテーブルが作成されました。
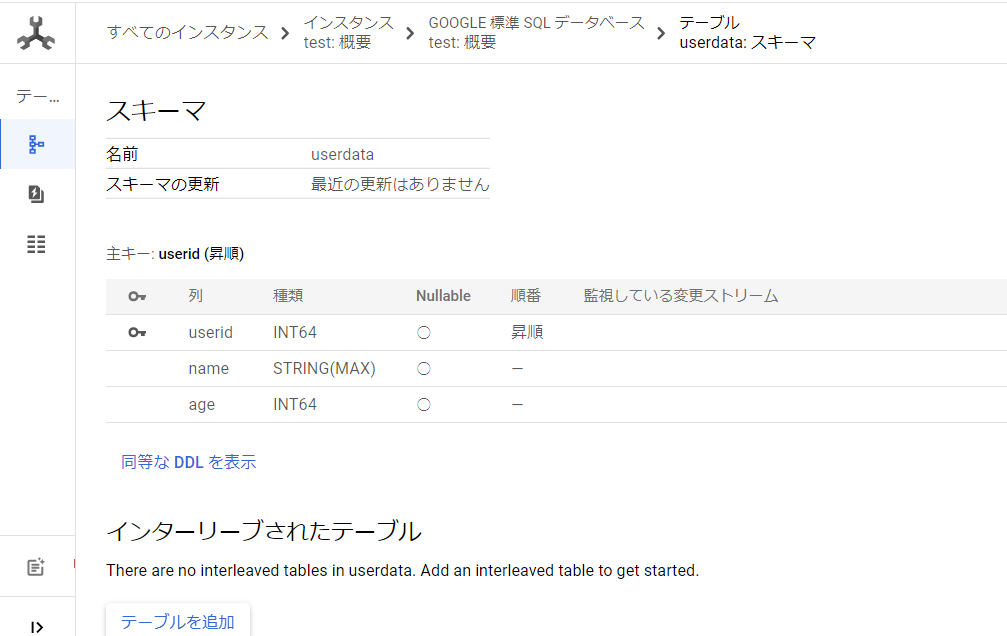
このようにSpannerではかんたんにデータベースを作成することが出来ます。
まとめ
Spannerとは、Google Cloudが提供する、かんたんに増えたり減ったりすることが出来る、リレーショナルデータベースです。